Toxicity in Gaming Communities
Let’s talk toxicity. When it comes to prevalent communities, especially competitive ones, toxicity becomes a big problem that affects the experience of the player. Nobody wants to play with a toxic player on their team, and sometimes the jokes and the “fun” get a little out of hand. I’ve even been the one to occasionally act in this manner with both the friends I’m playing with, and the opponents I’m playing against. It’s led to a lot of difficulties and has damaged the relationships I’ve had with others.
Let’s face it. Being toxic sucks for everyone.
As a member in many gaming communities, I wanted to gauge the toxicity of some of the most widely known games being currently played. I chose to look at League of Legends (LoL), World of Warcraft (WoW), and Final Fantasy XIV (FF14), as three cases for this project. The former two were well known for their toxicity, while the latter was known for being a very inclusive community. I used Reddit comments from each subreddit as the inputs to the model and performed a binary classification task to determine whether or not the comment was toxic.
Toxic Comment Dataset
To perform the classification task, I used the Jigsaw Toxic Comment Dataset to build a model. I then applied the same model to the curated set of Reddit comments for final analysis.
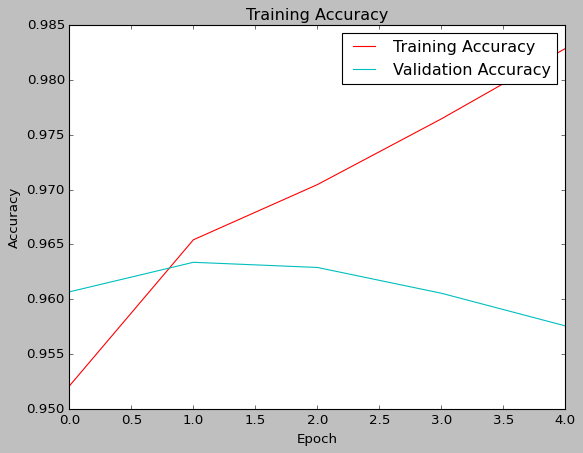
To solve the Jigsaw Toxic Comment Challenge, I used Tensorflow and Keras to implement an RNN with a word-embedding layer and bidirectional LSTMs. As the comments are a sequence of texts, this was a relatively standard model for solving NLP classification tasks.
The original dataset was a multiclass classification problem with data being specified as either “toxic”, “severely toxic”, “obscene”, “threats”, “insults”, and “identity hate”. Comments can be any of these, not necessarily just one. To simplify the problem, I reduced it to a binary classification task. This was to achieve better results in simply identifying toxic and nontoxic as opposed to determining the type of toxicity, although a well-trained model built on the original dataset could provide further insights.
The exact summary and hyperparameters of the model used can be found in the Jupyter notebook.
 |
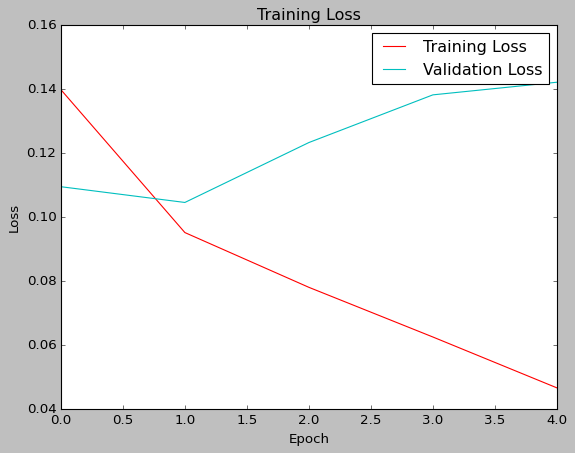 |
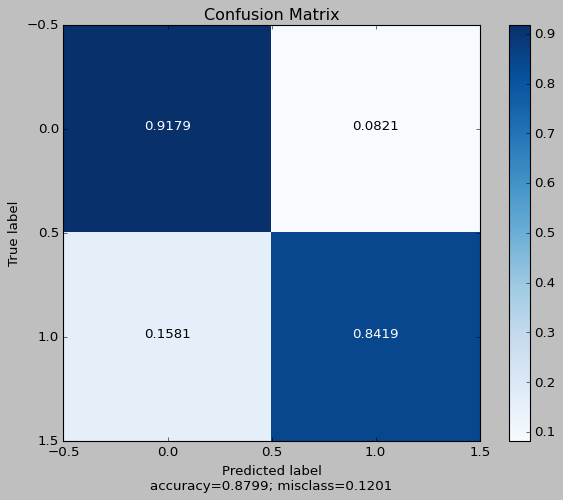
The initial training resulted in a model with the confusion matrix as follows. We see a final accuracy of 0.8799, and a misclass rate of 0.1201. This has an F1-score of 0.8843 and an MCC of 0.762.
To improve the model, we look at the Receiver-Operating Characteristic Curve (ROC) and the Area Under the Curve (AUC). This graph shows the performance of the model when the threshold is varied between 0 and 1. The closer to the top left corner, the better. As there is only one model being observed, we don’t need the AUC to determine anything in this situation, however the AUC would normally be used when comparing multiple models.
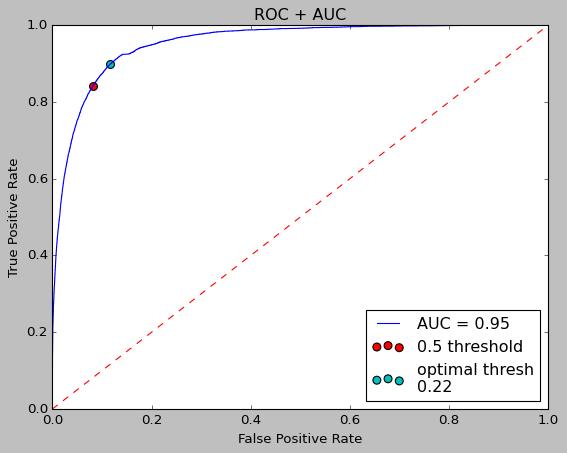
With the graph, the optimal threshold is 0.22. With the new threshold, we can generate a new confusion matrix to determine the performance of the optimized model.
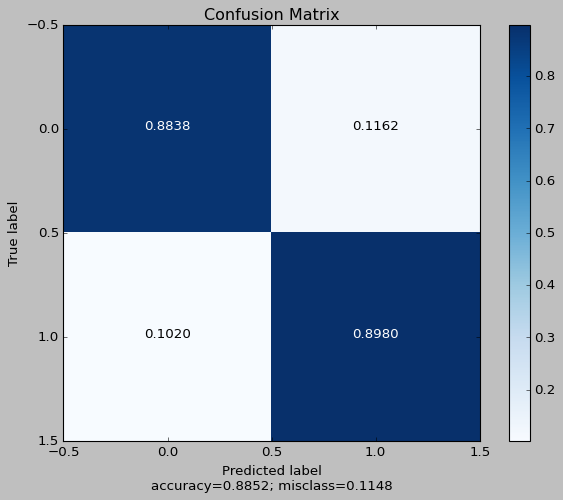
This model has a higher accuracy by better classifying true negatives at a smaller cost to the true positives, as shown by the optimization of the ROC/AUC. Naturally, the better model as an F1-score of 0.8901 and an MCC of 0.782.
This model is applied to the dataset of Reddit comments to determine the toxicity of the three subreddits.
Reddit Comments Data
A dataset of Reddit comments was curated using the Pushshift API. A weeks worth of comments from the three subreddits /r/ffxiv, /r/leagueoflegends/, and /r/wow were taken between 7/30/2020 to 8/6/2020. These dates were chosen as the most recent weeks worth of data at that time. Adding additional subreddits is simply a matter of pulling more data from the PushshiftAPI.
These comments were placed into a Pandas dataframe and padded before being passed into the model for classification. The end result was as follows:
Percentage of Comments that are Toxic in Subreddits
- FFXIV: 6.1791%
- WoW: 8.1006%
- LoL: 9.8211%
The results were similar to what I expected. FFXIV was known to have a more inclusive community, and thus, had a lesser portion of toxic comments than both WoW and LoL.
Future Work
Getting data from the subreddits and then labeling them into a dev-set would give a representation of how our model is doing on the actual data (subreddit comments). The current validation set and test set comes from the Jigsaw comment challenge, and is not of the same data distribution of subreddit comments. By having labeled data and then using a transfer learning approach, we can develop a model that performs better on the subreddit comments.
Also, tuning the model to perform better on the Jigsaw training-dev set could also provide a better starting point for our model.